SQL Code Conventions
T-SQL code must execute properly and performant. It must be readable, well laid out and it must be robust and resilient. It must not rely on deprecated features of SQL Server or assume specific database settings.
Table of contents
- Not Using Source Control
- Using ORM Instead of Stored Procedures
- Data Warehouse Date & Time Key Pattern
- UPSERT Pattern
- Using ORDER BY
- Not Parameterized Queries
- Cursors
- Using WHILE Loop
- Temporary Tables and Table Variables
- Using Hints
- Parameters or Variables Do Not Match Column Data Type
- When to Breakdown Complex Queries
- SQL Injection Risk
- Using Dynamic Search Conditions
- Using Brackets
- Using RANGE Instead of ROWS
- Using EXECUTE
- Unnecessarily Use of Common Table Expression CTE
- Using NOT IN in the WHERE Clause
- Using Correlated Subqueries Instead of Joins
- Excessive Use of Parentheses
- Using DATALENGTH to Find the Length of a String
- Using ‘== NULL’ or ‘<> NULL’ to Filter a Nullable Column
- Using the NOT IN Predicate in the WHERE Clause
- No Separate Environments
- Using Deprecated or Discontinued Feature
- Not Using Semicolon to Terminate Statements
- Using a Non-SARGable Expression in a WHERE Clause
- Using Unnecessary Functions
- Using Missing Indexes Recommendations
- Mixing Data Types in JOIN or WHERE Clauses
- Using RAISERROR Instead of THROW
- Not Using Semicolon THROW
- Not Using BEGIN END
- SET ANSI_NULLS OFF
- Using Types of Variable Length That Are Size 1 or 2
- Data Type Without Length
- COALESCE vs ISNULL
- Using ISNUMERIC
- Using SELECT DISTINCT
- Not Using SSIS
- IN/NOT VS EXISTS/NOT EXISTS
- Using Keyword Abbreviation
- Using Percent at the Start of LIKE Predicate
- Using Unfinished Notes
- Missing Index on WHERE Clause
- Missing Index on IN Columns
- Converting Dates to String to Compare
- Not Using SET XACT_ABORT ON
- Not Using Transactions
- Using Implicit Transactions
- Error Handling
- Scalar Function Is Not Inlineable
- Using User-Defined Scalar Function
- Not Using SET NOCOUNT ON in Stored Procedure or Trigger
- Using NOLOCK (READ UNCOMMITTED)
- Not Using Table Alias
- Not Using Column List For INSERT
- Not Using SQL Formatting
- Not Using UPPERCASE for Keywords
- Not Converting to Unicode
- Not Using lower case for Data Types
- Set Option Cause Recompile
- Using Column Number in ORDER BY
- Commented Out Code
- Not Using Location Comment
- Using Double Dash Instead of Block Comment
- Not Using Code Comments
- Not Using Table Schema
- Using SELECT *
- Using Hardcoded Database Name Reference
- Using @@IDENTITY Instead of SCOPE_IDENTITY
- Not Accounting for Time in a Range
- Using Non-ANSI NOT EQUAL Operator
- Using Old Sybase JOIN Syntax
- Not Specifying JOIN Type
- Using LEFT OUTER JOIN Instead of INNER JOIN
- Using INNER JOIN Instead of LEFT OUTER JOIN
- Order of Columns in JOIN Clause
- View Usage
- Invalid Objects
- JSON Explicit Schema
- JSON Performance
Not Using Source Control
Check Id: 73 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Your database objects (tables, views, stored procedures, functions, triggers, users, roles, schemas, static data, …) should be in a version control system.
Source control lets you see who made what changes, when, and why. Automate SQL changes during deployment. Rollback any changes you don’t want. Source control helps when you develop branch features.
Most importantly, you work from a single source of truth, greatly reducing the risk of downtime at deployment.
Your choices are Redgate SQL Source Control or a SSDT (SQL Server Data Tools) database project backed by DevOps or Github depending on the client requirments.
It is recommended that the database project source control be kept separate from application code. Database and reporting team members might/should not need access to the app source code. The data and business intelligence development team might have their own changes (performance tuning, data warehouse, reporting) in a “dev” branch, but their version is not ready for production yet.
Reasons to use a monorepo for multiple projects
- All the projects have the same permissions and access needs
- All the projects are fully aligned in terms of versioning
- All the projects must always be deployed together by the CI/CD pipeline(s)
- All the projects cannot be built separately unless they are in the same solution
If you choose to use a monorepo, please ensure you have accounted for the issues that can occur if not all the bullet points are fully true.
- See Should the Database and Application projects be in the same Repository? article by Eitan Blumin.
Using ORM Instead of Stored Procedures
Check Id: 74 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Put data access code (T-SQL) in the database and not in the application/ORM layer.
Utilizing an ORM or application generated database commands has downsides. ORM or app generated SQL code that sticks with basic CRUD (Create, Read, Update, Delete) are not too bad but they do not generate reasonable queries for reporting or beyond the basic CRUD commands.
The benefit of using stored procedures is with query performance tuning. Eventually the queries will outgrow the ORMs ability to generate optimal queries and execution plans. You end up attempting to rewrite software code to force the ORM to produce more performant SQL code.
With stored procedures there is a lot more options to tune a query. You can split up complex SQL code so the SQL Server engine can generate better execution plans, convert to dynamic SQL, use different hints, trace flags, and isolation levels, etc.
The free opensource sp_CRUDGen can be utilized to create 11 different stored procedures from basic your Create, Read, Update, Delete, Upsert stored procedures to extremely advanced safe dynamic Search stored procedures otherwise known as optional parameters, kitchen sink, Swiss army knife, catch-all queries. The generated stored procedure code utilizes the SQL Server community best practices.
- See Database-First: Stored Procedure in Entity Framework
- See Simple C# Data Access with Dapper and SQL - Minimal API Project Part 1
- See Simple C# Data Access with Dapper and SQL - Minimal API Project Part 2
Data Warehouse Date & Time Key Pattern
Check Id: 75 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
This data warehouse date & time key pattern can be used with the Date-Time-Number-Dimensions tables. The grain of the time dimension records is in seconds.
The primary keys in the date and time dimension tables are integers and the T-SQL below extracts and converts them.
If the datetime column in the source table is a datetimeoffset data type you can remove the first ‘AT TIME ZONE’.
SELECT
[Date Key] =
ISNULL(
CAST(
CONVERT(char(8),
CAST(
CAST(
GETDATE() AS datetime2(7) /* use the table date column instead of GETDATE() here */
)
AT TIME ZONE 'UTC' /* use this 1st AT TIME ZONE to set the offset if the data type is not using datetimeoffset(7) */
AT TIME ZONE 'Central Standard Time' /* this 2nd AT TIME ZONE converts into the time zone */
AS DATETIME
), 112
) AS INT
), -1
)
,[Time Key] =
REPLACE(
CONVERT(varchar(8),
CAST(
CAST(
GETDATE() AS datetime2(7) /* use the table date column instead of GETDATE() here */
)
AT TIME ZONE 'UTC' /* use this 1st AT TIME ZONE to set the offset if the data type is not using datetimeoffset(7) */
AT TIME ZONE 'Central Standard Time' AS TIME /* this 2nd AT TIME ZONE converts into the time zone */
), 108
), ':', ''
);
UPSERT Pattern
Check Id: 76 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Locating the row to confirm it exists is doing the work twice.
IF EXISTS (SELECT * FROM dbo.Person WHERE PersonId = @PersonId)
BEGIN
UPDATE dbo.Person SET FirstName = @FirstName WHERE PersonId = @PersonId;
END;
ELSE
BEGIN
INSERT dbo.Person (PersonId, FirstName) VALUES (@PersonId, @FirstName);
END;
Use this UPSERT pattern when a record update is more likely: Don’t worry about checking for a records existence just perform the update.
Consider using sp_CRUDGen to generate an UPSERT stored procedure at least as starting point.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
UPDATE
dbo.Person WITH (UPDLOCK, SERIALIZABLE)
SET
FirstName = 'Kevin'
WHERE LastName = 'Martin';
IF @@ROWCOUNT = 0
BEGIN
INSERT dbo.Person (FirstName, LastName) VALUES ('Kevin', 'Martin');
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;
Use this UPSERT pattern when a record insert is more likely: Don’t worry about checking for a records existence just perform the insert.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
INSERT dbo.Person
(
FirstName,
LastName
)
SELECT
'Kevin',
'Martin'
WHERE NOT EXISTS
(
SELECT
1
FROM dbo.Person WITH (UPDLOCK, SERIALIZABLE)
WHERE LastName = 'Martin'
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.Person SET FirstName = 'Kevin' WHERE LastName = 'Martin';
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;
Use this UPSERT pattern to allow the client application to handle the exception: Ensure you handle the exception in your code.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRANSACTION;
BEGIN TRY
INSERT dbo.Person (FirstName, LastName) VALUES ('Kevin', 'Martin');
END TRY
BEGIN CATCH
UPDATE dbo.Person SET FirstName = 'Kevin' WHERE LastName = 'Martin';
THROW;
END CATCH;
COMMIT TRANSACTION;
Use this UPSERT pattern for upserting multiple rows: You can use a table-valued parameter, JSON, XML or comma-separated list.
For JSON, XML or comma-separated list ensure you insert the records into a temporary table for performance considerations.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
/***************************************************************
** Create temp table to store the updates
****************************************************************/
CREATE TABLE #Update
(
FirstName varchar(50) NOT NULL,
LastName varchar(50) NOT NULL
);
INSERT INTO #Update
(
FirstName,
LastName
)
VALUES
('Kevin', 'Martin'),
('Jean-Luc', 'Picard');
/***************************************************************
** Perform Updates (WHEN MATCHED)
****************************************************************/
UPDATE
P WITH (UPDLOCK, SERIALIZABLE)
SET
P.FirstName = U.FirstName
FROM dbo.Person AS P
INNER JOIN #Update AS U
ON P.LastName = U.LastName;
/***************************************************************
** Perform Inserts (WHEN NOT MATCHED [BY TARGET])
****************************************************************/
INSERT dbo.Person
(
FirstName,
LastName
)
SELECT
U.FirstName,
U.LastName
FROM #Update AS U
WHERE NOT EXISTS
(
SELECT * FROM dbo.Person AS P WHERE P.LastName = U.LastName
);
/***************************************************************
** Perform Deletes (WHEN NOT MATCHED BY SOURCE)
****************************************************************/
DELETE P
FROM dbo.Person AS P
LEFT OUTER JOIN #Update AS U
ON P.LastName = U.LastName
WHERE U.LastName IS NULL;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;
Do not use this UPSERT pattern: It will produce primary key violations when run concurrently.
IF EXISTS (SELECT * FROM dbo.Person AS P WHERE P.LastName = 'Martin')
BEGIN
UPDATE dbo.Person
SET FirstName = 'Kevin'
WHERE LastName = 'Martin';
END;
ELSE
BEGIN
INSERT dbo.Person (FirstName, LastName)
VALUES ('Kevin', 'Martin');
END;
This UPSERT pattern can be problematic: In general, do not use MERGE statements in transactional (OLTP) databases, even though they are valid in ETL processes. If you do encounter MERGE statements in OLTP databases, be sure to address potential concurrency issues as described below. MERGE can be used for ETL processing if it is assured to NOT be run concurrently.
- See What To Avoid If You Want To Use MERGE article by Michael J. Swart
- See Use Caution with SQL Server’s MERGE Statement article by Aaron Bertrand
MERGE INTO dbo.Person WITH (HOLDLOCK) AS T
USING (
SELECT FirstName = 'Kevin', LastName = 'Martin'
) AS S
ON (S.LastName = T.LastName)
WHEN MATCHED AND EXISTS (
SELECT
S.FirstName
,S.LastName
EXCEPT
SELECT
T.FirstName
,T.LastName
) THEN
UPDATE SET
T.FirstName = S.FirstName
WHEN NOT MATCHED BY TARGET THEN
INSERT (FirstName, LastName)
VALUES
(S.FirstName, S.LastName)
WHEN NOT MATCHED BY SOURCE THEN
DELETE;
UPSERT Use case exception
If an update is not wanted for a reason like system-versioned temporal table history pollution the WITH (UPDLOCK, SERIALIZABLE) hint below should be used.
UPDLOCK is used to protect against deadlocks and let other session wait instead of falling victim a deadlock event. SERIALIZABLE will protect against changes to the data in the transaction and ensure no other transactions can modify data that has been read by the current transaction until the current transaction completes.
This method will not prevent a race condition and the last update will win.
BEGIN TRY
BEGIN TRANSACTION;
IF EXISTS (SELECT * FROM dbo.Person WITH (UPDLOCK, SERIALIZABLE) WHERE PersonId = @PersonId)
BEGIN
UPDATE dbo.Person SET FirstName = @FirstName WHERE PersonId = @PersonId;
END;
ELSE
BEGIN
INSERT dbo.Person (PersonId, FirstName) VALUES (@PersonId, @FirstName);
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;
Using ORDER BY
Check Id: 77 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
SQL Server is the second most expensive sorting system, remind the developer they can sort in the application layer
2020 Pricing
- Oracle Enterprise Edition = $47,500 per core
- Microsoft SQL Server Enterprise Edition = $7,128 per core
- ⬇
- Microsoft Access $159.99
Not Parameterized Queries
Check Id: 78 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Queries should be parameterized so SQL Server can reuse the execution plan. You application code is either hardcoding the query values in the WHERE clause or you are using some sort of dynamic T-SQL and not doing it correctly.
A temporary fix is to for parameterization until you can refactor the code and include some @parameters.
Cursors
Check Id: 79 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Overview
Even though you’ll hear DBAs and other experts say, “never use cursors!”, there are a few cases were cursors come in handy and there are a few important pointers.
SQL Server originally supported cursors to more easily port dBase II applications to SQL Server, but even then, you can sometimes use a WHILE loop (See Using WHILE Loop) as an effective substitute. Modern versions of SQL Server provide window functions and the CROSS/OUTER APPLY syntax to cope with some of the traditional valid uses of the cursor.
Valid Use Cases
- Executing a complex stored procedure or series of stored procedures based on a set of data. It is true this can be handled with a
WHILEloop and grabbing each record from the database, but a read-only, fast-forward cursor well and can be easier to manage. - Import scripts
Cursor Type
It is likely a bad idea to use any cursor other than one that is read-only and fast-forward. However, you need to declare your cursor correctly in order to create the right type: DECLARE MyCursor CURSOR LOCAL FAST_FORWARD FOR
Full Cursor Syntax
DECLARE
@MyId int
,@MyName nvarchar(50)
,@MyDescription nvarchar(MAX);
DECLARE MyCursor CURSOR LOCAL FAST_FORWARD FOR
SELECT
MT.MyId
,MT.MyName
,MT.MyDescription
FROM
dbo.MyTable AS MT
WHERE
MT.DoProcess = 1;
OPEN MyCursor;
FETCH NEXT FROM MyCursor
INTO
@MyId
,@MyName
,@MyDescription;
WHILE @@FETCH_STATUS = 0
BEGIN
--Do something or a series of things for each record
DECLARE @Result int;
EXEC @Result = dbo.SomeStoredProcedure @MyId = @MyId;
FETCH NEXT FROM MyCursor
INTO
@MyId
,@MyName
,@MyDescription;
END;
CLOSE MyCursor;
DEALLOCATE MyCursor;
Using WHILE Loop
Check Id: 80 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
WHILE loop is really a type of cursor. Although a WHILE loop can be useful for several inherently procedural tasks, you can usually find a better relational way of achieving the same results. The database engine is heavily optimized to perform set-based operations rapidly.
Here is a WHILE loop pattern. You might be able to create a SQL statement that does a bulk update instead.
CREATE TABLE #Person (
PersonId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(128) NOT NULL
,IsProcessed bit NOT NULL DEFAULT (0)
);
INSERT INTO
#Person (FirstName, LastName, IsProcessed)
VALUES
(N'Joel', N'Miller', 0);
DECLARE
@PersonId INT
,@FirstName nvarchar(100)
,@LastName nvarchar(100);
WHILE EXISTS (SELECT * FROM #Person WHERE IsProcessed = 0)
BEGIN
SELECT TOP (1)
@PersonId = P.PersonId
,@FirstName = P.FirstName
,@LastName = P.LastName
FROM
#Person AS P
WHERE
P.IsProcessed = 0
ORDER BY
P.PersonId ASC;
UPDATE
dbo.Person
SET
FirstName = @FirstName
,LastName = @LastName
WHERE
PersonId = @PersonId;
UPDATE #Person SET IsProcessed = 1 WHERE PersonId = @PersonId;
END;
Temporary Tables and Table Variables
Check Id: 81 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use Temporary Tables and not Table Variables.
- There is optimization limitations like lack of statistics that very frequently lead to performance issues. The advice of “use table variables if you have less than NNN rows” is flawed. It might seem like temporary tables are performant, but they are not scalable with a couple more years of data.
- There are two use cases for table variable and are infrequently called for.
- Extremely highly called code where recompiles from temporary table activity is a problem
- Audit scenarios when you need to keep data after a transaction is rolled back.
Do This:
CREATE TABLE #UseMe (
UseMeId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(100) NOT NULL
);
Instead Of:
DECLARE @DoNotUseMe table (
DoNotUseMeId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(100) NOT NULL
);
Using Hints
Check Id: 82 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend that hints be used only as a last resort by experienced developers and database administrators.
Parameters or Variables Do Not Match Column Data Type
Check Id: 83 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Parameters and variables should match the column data type, length, and precision.
The example below is how not to create parameters and variables with mismatching types and lengths.
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction (
@FirstName AS nvarchar(100) /* ← 100 characters */
)
AS
BEGIN
SET NOCOUNT ON;
/* ↓ 50 characters */
SELECT LastName FROM dbo.Person WHERE FirstName = @FirstName;
/* ↓ 100 characters and varchar() */
DECLARE @LastName AS varchar(100) = N'martin'
/* ↓ 50 characters and nvarchar() */
SELECT FirstName FROM dbo.Person WHERE LastName = @LastName;
END;
When to Breakdown Complex Queries
Check Id: 84 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Source: When To Break Down Complex Queries
Microsoft SQL Server is able to create very efficient query plans in most cases. However, there are certain query patterns that can cause problems for the query optimizer; this paper describes four of these patterns. These problematic query patterns generally create situations in which SQL Server must either make multiple passes through data sets or materialize intermediate result sets for which statistics cannot be maintained. Or, these patterns create situations in which the cardinality of the intermediate result sets cannot be accurately calculated.
Breaking these single queries into multiple queries or multiple steps can sometimes provide SQL Server with an opportunity to compute a different query plan or to create statistics on the intermediate result set. Taking this approach instead of using query hints lets SQL Server continue to react to changes in the data characteristics as they evolve over time.
Although the query patterns discussed in this paper are based on customer extract, transform, and load (ETL) and report jobs, the patterns can also be found in other query types.
This paper focuses on the following four problematic query patterns:
OR logic in the WHERE clause
In this pattern, the condition on each side of the OR operator in the WHERE or JOIN clause evaluates different tables. This can be resolved by use of a UNION operator instead of the OR operator in the WHERE or JOIN clause.
Aggregations in intermediate results sets
This pattern has joins on aggregated data sets, which can result in poor performance. This can be resolved by placing the aggregated intermediate result sets in temporary tables.
A large number of very complex joins
This pattern has a large number of joins, especially joins on ranges, which can result in poor performance because of progressively degrading estimates of cardinality. This can be resolved by breaking down the query and using temporary tables.
A CASE clause in the WHERE or JOIN clause
This pattern has CASE operators in the WHERE or JOIN clauses, which cause poor estimates of cardinality. This can be resolved by breaking down the cases into separate queries and using the Transact-SQL IF statement to direct the flow for the conditions.
An understanding of the concepts introduced in these four cases can help you identify other situations in which these or similar patterns are causing poor or inconsistent performance; you can then construct a replacement query which will give you better, more consistent performance.
SQL Injection Risk
Check Id: 85 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
SQL injection is an attack in which malicious code is inserted into strings that are later passed to an instance of SQL Server for parsing and execution. Any procedure that constructs SQL statements should be reviewed for injection vulnerabilities because SQL Server will execute all syntactically valid queries that it receives. Even parameterized data can be manipulated by a skilled and determined attacker.
- Source SQL Injection
- See Using EXECUTE
Using Dynamic Search Conditions
Check Id: 86 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
aka. Catch-All Query or Kitchen Sink Query
If your stored procedure has multiple parameters where any one (or more) number are parameters are optional, you have a dynamic search query.
If your query is moderately complex you should use OPTION (RECOMPILE). If your query is complex, you should build the query with dynamic SQL.
You will also know this based on the WHERE clause of the query. You will see @ProductId IS NULL or have parameters wrapped in an ISNULL().
CREATE PROCEDURE dbo.SearchHistory
@ProductId int = NULL
,@OrderId int = NULL
,@TransactionType char(1) = NULL
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
TH.ProductId
FROM
dbo.TransactionHistory AS TH
WHERE
(TH.ProductId = @ProductId OR @ProductId IS NULL)
AND (TH.ReferenceOrderId = @OrderId OR @OrderId IS NULL)
AND (TH.TransactionType = @TransactionType OR @TransactionType IS NULL)
AND (TH.Quantity = ISNULL(@childFilter, m.Child));
END;
IF Branches are not a Viable Fix
The problem is that we already have a query plan when we hit the IF @CreationDate IS NULL segment of TSQL.
CREATE OR ALTER PROCEDURE dbo.PersonSearch (@CreationDate datetime2(7) = NULL)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @CreationDate IS NULL
BEGIN
SET @CreationDate = '20080101';
END;
SELECT FirstName, LastName FROM dbo.Person WHERE CreationDate = @CreationDate;
END;
For simple to moderately complex queries add OPTION (RECOMPILE).
CREATE PROCEDURE dbo.SearchHistory
@ProductId int = NULL
,@OrderId int = NULL
,@TransactionType char(1) = NULL
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
TH.ProductId
FROM
dbo.TransactionHistory AS TH
WHERE
(TH.ProductId = @ProductId OR @ProductId IS NULL)
AND (TH.ReferenceOrderId = @OrderId OR @OrderId IS NULL)
AND (TH.TransactionType = @TransactionType OR @TransactionType IS NULL)
AND (TH.Quantity = ISNULL(@childFilter, m.Child))
OPTION (RECOMPILE)/* <-- Added this */;
END;
- See Dynamic Search Conditions in T‑SQL by Erland Sommarskog
Consider using sp_CRUDGen to generate the dynamic SQL query for you.
Using Brackets
Check Id: 87 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You might be using square brackets [] unnecessarily for object names. If object names are valid and not reserved words, there is no need to use square brackets. Use them only for invalid names.
SELECT
P.[FirstName]
,P.[MiddleName]
,P.[LastName]
FROM
[dbo].[Person] AS P
/* Use this instead */
SELECT
P.FirstName
,P.MiddleName
,P.LastName
FROM
dbo.Person AS P
Using RANGE Instead of ROWS
Check Id: 88 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The default window function frame RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW is less performant than ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
Source: What is the Difference between ROWS and RANGE?
Using EXECUTE
Check Id: 89 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Do not use EXECUTE('SQL script'); to execute T-SQL command. The EXEC() command is retained for backward compatibility and is susceptible to SQL injection.
Instead use sp_executesql as it allows parameter substitutions. Using parameters allows SQL Server to reuse the execution plan and avoid execution plan pollution.
Unnecessarily Use of Common Table Expression CTE
Check Id: 90 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use a Common Table Expression (CTE) to make SQL statements easier to understand and for recursive statements. Generally anything beyond basic use of CTEs provide extra overhead and cause performance issues.
A CTE will be evaluated every time you reference it. If a CTE is referenced only once it will give the same performance as a temporary table or subquery.
Using NOT IN in the WHERE Clause
Check Id: 91 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
When you utilize NOT IN in your WHERE clause the SQL Server optimizer will likely perform a table scan instead of an index seek. Index seeks are generally more performant than table scans.
Try rewriting the query to use LEFT OUTER JOIN and check for NULL on the right-handed side table.
Using Correlated Subqueries Instead of Joins
Check Id: 92 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Correlated subqueries can have a performance impact. Most correlated subqueries can be rewritten with joins or window functions and perform much faster.
See SQL Server Uncorrelated and Correlated Subquery
Excessive Use of Parentheses
Check Id: 93 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Excessive use of parentheses makes code difficult to understand and maintain.
Using DATALENGTH to Find the Length of a String
Check Id: 94 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
DATALENGTH() can give you an incorrect length with fixed length data types like char(). Use LEN()
Sample Query
DECLARE @FixedString AS char(10) = 'a';
SELECT
WrongLength = DATALENGTH(@FixedString)
,CorrectLength = LEN(@FixedString);
Query Results
| WrongLength | CorrectLength |
|---|---|
| 10 | 1 |
Using ‘== NULL’ or ‘<> NULL’ to Filter a Nullable Column
Check Id: 95 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
To determine whether an expression is NULL, use IS NULL or IS NOT NULL instead of comparison operators (such as = or <>). Comparison operators return UNKNOWN when either or both arguments are NULL.
Using the NOT IN Predicate in the WHERE Clause
Check Id: 96 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use EXISTS instead of IN.
EXISTS used to be faster than IN when comparing data from a subquery. Using EXISTS would stop searching as soon as it found the first row. IN would collect all the results. SQL Server got smarter and treats EXISTS and IN the same way so performance is not an issue.
The NOT IN operator cause issues when the subquery data contains NULL values. NOT EXIST or LEFT JOIN / IS NULL should be used.
Option 2 (LEFT JOIN / IS NULL) & 3 (NOT EXISTS) are semantically equivalent.
/* Option 1 (NOT IN)*/
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
WHERE
P.PersonId NOT IN (SELECT L.PersonId FROM dbo.List AS L);
/* Option 2 (LEFT JOIN / IS NULL) */
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
LEFT OUTER JOIN dbo.List AS L ON P.PersonId = L.PersonId
WHERE
L.PersonId IS NULL;
/* Option 3 (NOT EXISTS) */
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
WHERE
NOT EXISTS (SELECT * FROM dbo.List AS L WHERE P.PersonId = L.PersonId);
No Separate Environments
Check Id: 97 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You should have a Development, Testing & Production environment.
SQL Server development is a continuous process to avoid the issues caused by development and reducing the risks of blocking business.
Accidents happen! Imagine you accidentally made an update to thousands of records that you cannot undo without hours of work. Imagine that you do not have access to original data before you changed it. Feeling scared yet? This is where a development and test environment save effort.
A development environment allows developers to program and perform test ensuring their code is correct before pushing to a centralized testing environment for UAT (User Acceptance Testing) or staging for production.
Using Deprecated or Discontinued Feature
Check Id: 98 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
When a feature is marked deprecated, it means:
- The feature is in maintenance mode only. No new changes will be done, including those related to addressing inter-operability with new features.
- We strive not to remove a deprecated feature from future releases to make upgrades easier. However, under rare situations, we may choose to permanently discontinue (remove) the feature from SQL Server if it limits future innovations.
- For new development work, do not use deprecated features. For existing aplications, plan to modify applications that currently use these features as soon as possible.
A discontinued feature means it is no longer available. If a discontinued feature is being used, when we upgrade to a new SQL Server version, the code will break.
See:
- Deprecated database engine features in SQL Server 2019
- Deprecated Database Engine Features in SQL Server 2017
- Deprecated Database Engine Features in SQL Server 2016
- Discontinued Database Engine Functionality in SQL Server 2014
- Discontinued Features in SQL Server 2012
Not Using Semicolon to Terminate Statements
Check Id: 99 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Although the semicolon isn’t required for most statements prior to SQL Server 2016, it will be required in a future version. If you do not include them now database migration in the future will need to add them. Terminating semicolon are required by the ANSI SQL Standard.
Continued use of deprecated features will cause database migrations to fail. An example is RAISERROR in the format RAISERROR 15600 'MyCreateCustomer'; is discontinued. RAISERROR (15600, -1, -1, 'MyCreateCustomer'); is the current syntax. A database will not migrate to a newer SQL Server version without refactoring the TSQL code.
For new development work, do not use deprecated features. For existing aplications, plan to modify applications that currently use these features as soon as possible. See Microsoft Docs.
SET NOCOUNT, XACT_ABORT ON; /* <-- semicolon goes at the end here */
DECLARE @FirstName nvarchar(100); /* <-- semicolon goes at the end here */
SET @FirstName = N'Kevin'; /* <-- semicolon goes at the end here */
SELECT LastName FROM dbo.Person WHERE FirstName = @FirstName; /* <-- semicolon goes at the end here */
SELECT Balance FROM dbo.Account; /* <-- semicolon goes at the end here */
IF EXISTS (SELECT * FROM dbo.Person)
BEGIN
SELECT PersonId, FirstName, LastName FROM dbo.Person; /* <-- semicolon goes at the end here */
END; /* <-- semicolon goes at the end here */
BEGIN TRY
BEGIN TRANSACTION; /* <-- semicolon goes at the end here */
UPDATE dbo.Account SET Balance = 100.00 WHERE AccountId = 1; /* <-- semicolon goes at the end here */
UPDATE dbo.Account SET Balance = 'a' WHERE AccountId = 2; /* <-- semicolon goes at the end here */
COMMIT TRANSACTION; /* <-- semicolon goes at the end here */
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION; /* <-- semicolon goes at the end here */
END; /* <-- semicolon goes at the end here */
THROW; /* <-- semicolon goes at the end here */
END CATCH; /* <-- semicolon goes at the end here */
Using a Non-SARGable Expression in a WHERE Clause
Check Id: 100 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Search ARGument..able. Avoid having a column or variable used within an expression or used as a function parameter. You will get a table scan instead of an index seek which will hurt performance.
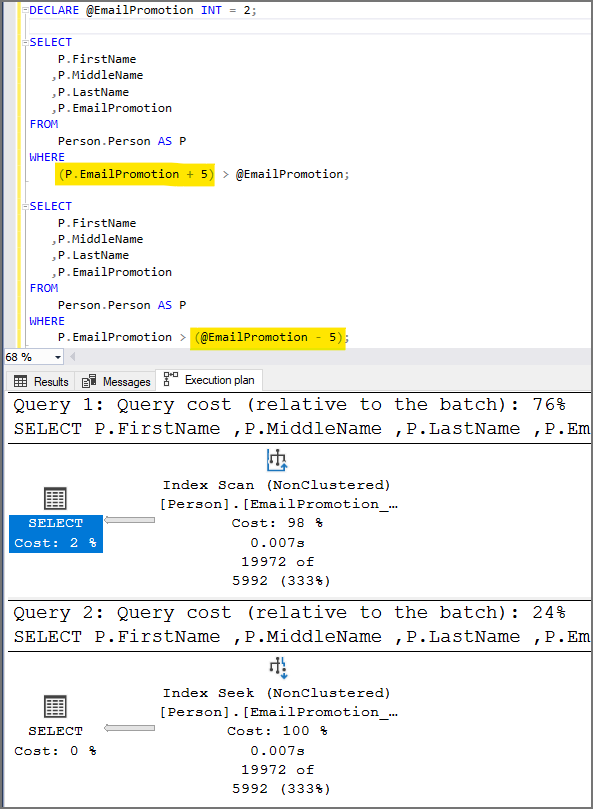
Another issue with non-sargable queries besides the forced table scan is SQL Server will not be able to provide a recommended index.
Changing the WHERE clause to not use the YEAR() function and doing a bit more typing allows SQL Server to understand what you want it to do.
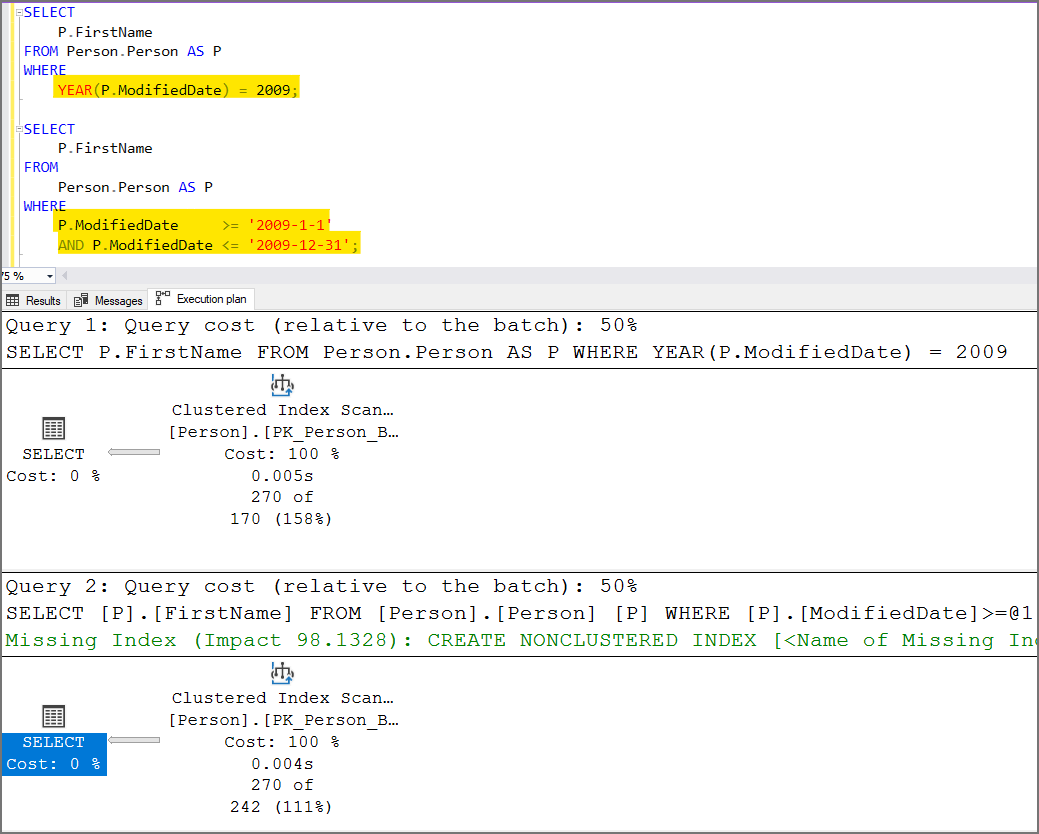
Using Unnecessary Functions
Check Id: 101 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
- Use
TRIM(string)instead ofLTRIM(RTRIM(string)) - When comparing a string for blank it is unnecessary to trim the string before the comparison. The examples below are two ways to check for parameter/variable blanks.
DECLARE @String nvarchar(100) = N' '
IF @String = N''
BEGIN
/* Do the thing here */
END
IF LEN(@String) = 0
BEGIN
/* Do the thing here */
END
- If your database is set to ‘case insensitive’, you do not need to use the
LOWER(string)function when comparing two strings.- Execute the query
SELECT CONVERT(varchar(256), SERVERPROPERTY('collation'));to verify the database shows it is a ‘case insensitive’ collation (_CI_). The default SQL Server collation is ‘SQL_Latin1_General_CP1_CI_AS’.
- Execute the query
Using Missing Indexes Recommendations
Check Id: 102 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The SQL Server Missing Indexes recommendations feature has limitations and even recommends you create indexes that already exist. It is not meant for you fine tune and only provides sometimes adequate recommendations.
You should assess the missing index recommendation but create a fine-tuned custom index that includes all that is excluded items.
See the Books Online: Limitations of the Missing Indexes Feature
The missing index feature has the following limitations:
- It is not intended to fine tune an indexing configuration.
- It cannot gather statistics for more than 500 missing index groups.
- It does not specify an order for columns to be used in an index.
- For queries involving only inequality predicates, it returns less accurate cost information.
- It reports only include columns for some queries, so index key columns must be manually selected.
- It returns only raw information about columns on which indexes might be missing.
- It does not suggest filtered indexes.
- It can return different costs for the same missing index group that appears multiple times in XML Showplans.
- It does not consider trivial query plans.
Mixing Data Types in JOIN or WHERE Clauses
Check Id: 103 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Mixing data types cause implicit conversion and they are bad for performance. Implicit conversions ruin SARGability, makes index unusable and utilize more CPU resource than required.
In the WHERE clause below you will notice the “!” mark on the SELECT indicating there is an implicit conversion. In this example the EmailPromotion column is an INT but we are treating it like a string by performing a LIKE. We get a slow table scan instead of a faster index seek.
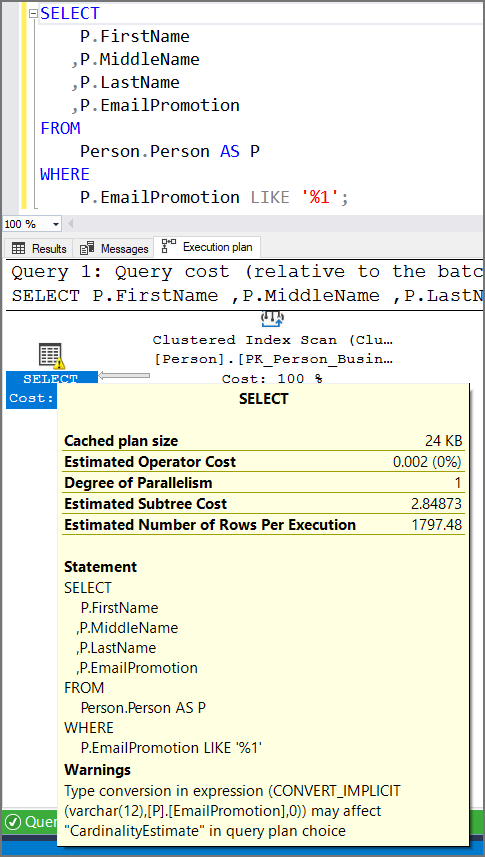
Using RAISERROR Instead of THROW
Check Id: 104 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
New applications should use THROW instead of RAISERROR
The RAISERROR statement does not honor SET XACT_ABORT.
RAISERROR never aborts execution, so execution will continue with the next statement.
A use case exception for using RAISERROR instead of THROW is for legacy compatibility reasons. THROW was introduced in SQL Server 2012 so when making modification on this code THROW can break the current code.
Not Using Semicolon THROW
Check Id: 105 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
THROW is not a reserved keyword so it could be used as a transaction name or savepoint. Always use a BEGIN...END block after the IF statement in the BEGIN CATCH along with a terminating semicolon.
Use this:
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
SELECT 1 / 0;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;
Instead of this:
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
SELECT 1 / 0;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION
THROW;
END CATCH;
Not Using BEGIN END
Check Id: 106 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The BEGIN...END control-of-flow statement block is optional for stored procedures and IF statements but is required for multi-line user-defined functions. It is best to avoid confusion and be consistent and specific.
IF Statements
Always included BEGIN...END blocks for IF statements with a semicolon to terminate the statement. Using BEGIN...END in an IF statement and semicolon is critical in some cases.
Use this:
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
Instead of this:
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;
Instead of this:
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION;
Stored Procedures
Use this:
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction
AS
BEGIN
SET NOCOUNT ON;
/* [T-SQL GOES HERE] */
END;
GO
Instead of this:
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction
AS
SET NOCOUNT ON;
/* [T-SQL GOES HERE] */
GO
SET ANSI_NULLS OFF
Check Id: 107 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You should be using SET ANSI_NULLS ON; unless you have a good reason not to.
Using Types of Variable Length That Are Size 1 or 2
Check Id: 108 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
If the length of the type will be very small (size 1 or 2) and consistent, declare them as a type of fixed length, such as char, nchar, and binary.
When you use data types of variable length such as varchar, nvarchar, and varbinary, you incur an additional storage cost to track the length of the value stored in the data type. In addition, columns of variable length are stored after all columns of fixed length, which can have performance implications.
Data Type Without Length
Check Id: 109 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Always specify lengths for a data type.
- A
varchar, ornvarcharthat is declared without an explicit length will use a default length. It is safer to be explicit. decimal,numeric. If no precision and scale are provided, SQL Server will use (18, 0), and that might not be what you want.- Explicitly define data type default lengths instead of excluding them.
- [n][var]char(1) or [n][var]char(30)
- The default length is 1 when n isn’t specified in a data definition or variable declaration statement. When n isn’t specified with the CAST function, the default length is 30.
- datetime2(7)
- datetimeoffset(7)
- float(53)
- [var]binary(1) or [var]binary(30)
- The default length is 1 when n isn’t specified in a data definition or variable declaration statement. When n isn’t specified with the CAST function, the default length is 30.
- [n][var]char(1) or [n][var]char(30)
COALESCE vs ISNULL
Check Id: 110 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The ISNULL function and the COALESCE expression have a similar purpose but can behave differently.
- Because
ISNULLis a function, it’s evaluated only once. As described above, the input values for theCOALESCEexpression can be evaluated multiple times. - Data type determination of the resulting expression is different.
ISNULLuses the data type of the first parameter,COALESCEfollows theCASEexpression rules and returns the data type of value with the highest precedence. - The NULLability of the result expression is different for
ISNULLandCOALESCE. - Validations for
ISNULLandCOALESCEare also different. For example, a NULL value forISNULLis converted to int though forCOALESCE, you must provide a data type. ISNULLtakes only two parameters. By contrastCOALESCEtakes a variable number of parameters.
Source: Microsoft Docs: Comparing COALESCE and ISNULL
Using ISNUMERIC
Check Id: 111 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Avoid using the ISNUMERIC() function, because it can often lead to data type conversion errors. If you’re working on SQL Server 2012 or later, it’s much better to use the TRY_CONVERT() or TRY_CAST() function instead. On earlier SQL Server versions, the only way to avoid it is by using LIKE expressions.
Using SELECT DISTINCT
Check Id: 112 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
So, while DISTINCT and GROUP BY are identical in a lot of scenarios, there is one case where the GROUP BY approach leads to better performance (at the cost of less clear declarative intent in the query itself).
You also might be using SELECT DISTINCT to mask a JOIN problem. It’s much better to determine why rows are being duplicated and fix the problem.
- See: Performance Surprises and Assumptions : GROUP BY vs. DISTINCT by Aaron Bertrand
Not Using SSIS
Check Id: 113 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use SSIS (SQL Server Integration Service) to move data around. You can use stored procedures and SQL Server Agent Jobs instead of SSIS to ETL data, but it will make it difficult to orchestrate tasks between different environments.
SSIS gives you the ability to create project and package parameters that can be configured in the SSIS catalog Environments. SSIS has built in logging and Execution run reports you can access from SSMS (SQL Server Management Studio).
When it comes time to migrate to Azure you can lift and shift you SSIS packages to an Azure-SSIS Integration Runtime.
IN/NOT VS EXISTS/NOT EXISTS
Check Id: 114 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use EXISTS or NOT EXISTS if referencing a subquery, and IN/NOT IN when using a list of literal values.
Using Keyword Abbreviation
Check Id: 115 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use the full name like in DATEDIFF(YEAR, StartDate, EndDate) vs DATEDIFF(YY, StartDate, EndDate).
Using Percent at the Start of LIKE Predicate
Check Id: 116 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You will not get an index seek using the percent wildcard (%) first in your search predicate.
SELECT
P.FirstName
,P.MiddleName
,P.LastName
FROM
dbo.Person AS P
WHERE
P.LastName LIKE '%son';
Using Unfinished Notes
Check Id: 117 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You might still have some work to do. One of the codetags below was found.
- TODO
- FIXME
- HACK
- CLEVER
- MAGIC
- XXX
- BUG
- BUGFIX
- OPTIMIZE
- LAZY
- BROKEN
- REFACTOR
- REFACT
- RFCTR
- OOPS
- SMELL
- NEEDSWORK
- INSPECT
- RFE
- FEETCH
- FR
- FTRQ
- FTR
- IDEA
- QUESTION
- QUEST
- QSTN
- WTF
- ???
- !!!
- NOTE
- HELP
- TODOC
- DOCDO
- DODOC
- NEEDSDOC
- EXPLAIN
- DOCUMENT
Missing Index on WHERE Clause
Check Id: 118 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Check WHERE clauses for columns that are not included in an index. Might also want to exclude check for tables with small (5k or less) number of records.
Missing Index on IN Columns
Check Id: 119 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Check IN() predicates for columns that are not included in an index. Might also want to exclude check for tables with small (5k or less) number of records.
Converting Dates to String to Compare
Check Id: 120 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Don’t convert dates to strings to compare. Dates should be stored with the pattern YYYY-MM-DD. Not all are and string comparisons can provide the wrong results.
Not Using SET XACT_ABORT ON
Check Id: 121 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
- When
SET XACT_ABORT ON, if a T-SQL statement raises a run-time error, the entire transaction is terminated and rolled back. - When
SET XACT_ABORT OFF, in some cases only the T-SQL statement that raised the error is rolled back and the transaction continues processing. Depending upon the severity of the error, the entire transaction may be rolled back even when SET XACT_ABORT is OFF. OFF is the default setting in a T-SQL statement, while ON is the default setting in a trigger.
A use case for SET XACT_ABORT OFF is when debugging to trap an error.
Not Using Transactions
Check Id: 122 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Transactions allow for database operations to be atomic. A group of related SQL commands that must all complete successfully or not at all and must be rolled back.
If you are performing a funds transfer and updating multiple bank account tables with debiting one and crediting the other, they must all complete successfully or there will be an imbalance.
Here is a basic transaction pattern.
SET NOCOUNT, XACT_ABORT ON;
/* Exclude SQL code that does not need to be inclued in the transaction. Keep transactions shrt. */
BEGIN TRY
BEGIN TRANSACTION;
UPDATE dbo.Account SET Balance = -100.00 WHERE AccountId = 1;
UPDATE dbo.Account SET Balance = 'not a decimal' WHERE AccountId = 2;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
Here is transaction pattern with a custom THROW error.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
DECLARE @ErrorMessageText nvarchar(2048);
BEGIN TRANSACTION;
/* Debit the first account */
UPDATE dbo.Account SET Balance = -100.00 WHERE AccountId = 1;
/* Check the first account was debited */
IF @@ROWCOUNT <> 1
BEGIN
SET @ErrorMessageText = N'The debited account failed to update.';
END;
/* Credit the second account */
UPDATE dbo.Account SET Balance = 100.00 WHERE AccountId = 2;
/* Check the second account was credited */
IF @@ROWCOUNT <> 1
BEGIN
SET @ErrorMessageText = N'The credited account failed to update.';
END;
/* Check if we have any errors to throw */
IF @ErrorMessageText <> ''
BEGIN
; THROW 50001, @ErrorMessageText, 1;
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
- See Not Using SET XACT_ABORT ON
- See Not Using BEGIN END
- See Not Using Semicolon THROW
- See Using RAISERROR Instead of THROW
Using Implicit Transactions
Potential Finding:
Check Id: 39 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Do not use SET IMPLICIT_TRANSACTIONS ON
The default behavior of SQL Servers is IMPLICIT_TRANSACTIONS OFF that does not keep TSQL commands open waiting for a ROLLBACK TRANSACTION or COMMIT TRANSACTION command. When OFF, we say the transaction mode is autocommit.
When IMPLICIT_TRANSACTIONS ON is used, it could appear that the command finished instantly, but there will be an exclusive lock on the row(s) until either a roll back or commit command is issued. This makes IMPLICIT_TRANSACTIONS ON is not popular as they can cause considerable blocking and locking.
When a connection is operating in implicit transaction mode (IMPLICIT_TRANSACTIONS ON), the instance of the SQL Server Database Engine automatically starts a new transaction after the current transaction is committed or rolled back. You do nothing to delineate the start of a transaction; you only commit or roll back each transaction. Implicit transaction mode generates a continuous chain of transactions.
- See Transaction locking and row versioning guide > Implicit Transactions
- See SET IMPLICIT_TRANSACTIONS ON Is One Hell of a Bad Idea
Error Handling
Check Id: 123 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
There are different methodologies for handling errors that originate in a database. New applications should use the THROW methodologies.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
The sample stored procedures below can be used to wire up and test software code to ensure errors are bubbled up, and the user is notified, and error data is logged. After each sample stored procedure below is commented out code to execute each of them.
THROW Methodology (dbo.TestTHROW)
This error catching and trowing methodology is the newest. THROW, introduced in SQL Server 2012 and raises an exception and transfers execution to a CATCH block of a TRY...CATCH construct.
Return Code Methodology (dbo.TestReturnCode)
The return code methodology utilizes RETURN. RETURN, exits unconditionally from a query or procedure. RETURN is immediate and complete and can be used at any point to exit from a procedure, batch, or statement block. Statements that follow RETURN are not executed.
When THROW is utilized, a return code is not assigned. RETURN was commonly utilized with RAISERROR which never aborts execution, so RETURN could be used afterwards. (See Using RAISERROR Instead of THROW). Utilizing RAISERROR with the return code would provide context to the error that occurred to present to the user and log the error.
Output Parameter Methodology (dbo.TestReturnCodeParameter)
This methodology utilizes stored procedure OUTPUT parameters. Here you can set a return code and a return message that is passed back to the software code to present to the user and log the error
RAISERROR Methodology (dbo.TestRAISERROR)
New applications should use THROW instead of RAISERROR
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestTHROW (
@ThowSystemError bit = 0
,@ThowCustomError bit = 0
,@ThrowMultipleErrors bit = 0 /* Only works on SQL Server and not Azure SQL Databases. */
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ThowSystemError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe1;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
IF @ThowCustomError = 1
BEGIN
DECLARE @ErrorMessageText nvarchar(2048);
BEGIN TRY
BEGIN TRANSACTION;
SELECT JustAOne = 1 INTO
#IgnoreMe2;
/* Custom error check */
IF @@ROWCOUNT = 1
BEGIN
SET @ErrorMessageText = N'Two rows were expected to be impacted.';
END;
/* Another custom error check */
IF @@ROWCOUNT = 3
BEGIN
/* https://docs.microsoft.com/en-us/sql/t-sql/language-elements/throw-transact-sql?view=sql-server-ver15#c-using-formatmessage-with-throw */
SET @ErrorMessageText = N'Three rows were expected to be impacted.';
END;
/* Check if we have any errors to throw */
IF @ErrorMessageText <> ''
BEGIN
; THROW 50001, @ErrorMessageText, 1;
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
IF @ThrowMultipleErrors = 1
BEGIN
BEGIN TRY
BACKUP DATABASE master TO DISK = 'E:\FOLDER_NOT_EXISTS\test.bak';
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int = NULL;
EXECUTE @ReturnCode = dbo.TestTHROW
-- Set both parameters to 0 (zero) will not throw an error --
@ThowSystemError = 0 -- Set to 1 will throw a system generated error (8134: Divide by zero error encountered.) --
,@ThowCustomError = 0 -- Set to 1 will throw a custom error (50001: Two rows were expected to be impacted.) --
,@ThrowMultipleErrors = 0; -- Set to 1 will throw multiple error (3201: Cannot open backup device...) OR (911: Database 'AdventureWorks2019' does not exist. Make sure that the name is entered correctly.) AND (3013: BACKUP DATABASE is terminating abnormally.) NOTE: Will not work on an Azure SQL Database. --
-- NOTE: There is no return code when an error is THROWN --
SELECT ReturnCode = @ReturnCode;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestReturnCode (
@ReturnDefaultReturnCode bit = 0
,@ReturnSystemErrorReturnCode bit = 0
,@ReturnCustomReturnCode bit = 0
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ReturnDefaultReturnCode = 1
BEGIN
/* The return code will automatically be 0 (zero) even if it is not specified */
SELECT JustAOne = 1 INTO
#IgnoreMe1;
END;
IF @ReturnSystemErrorReturnCode = 1
BEGIN
BEGIN TRY
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RETURN ERROR_NUMBER();
END CATCH;
END;
IF @ReturnCustomReturnCode = 1
BEGIN
DECLARE @ReturnCode int;
SELECT JustAOne = 1 INTO
#IgnoreMe3;
IF @@ROWCOUNT <> 2
BEGIN
SET @ReturnCode = 123123;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RETURN @ReturnCode;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int;
EXECUTE @ReturnCode = dbo.TestReturnCode
@ReturnDefaultReturnCode = 0 -- Set to 1 to see the default return code 0 (zero). All parameters set to 0 will also be the default return code of 0 (zero). --
,@ReturnSystemErrorReturnCode = 0 -- Set to 1 to see a system error return code (8134:) --
,@ReturnCustomReturnCode = 0; -- Set to 1 to see a custom return code (123123:) --
SELECT ReturnCode = @ReturnCode;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestReturnCodeParameter (
@ReturnError bit = 0
,@ReturnCode int = 0 OUTPUT
,@ReturnMessage nvarchar(2048) = N'' OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ReturnError = 0
BEGIN
SET @ReturnCode = 0;
SET @ReturnMessage = N'';
END;
ELSE
BEGIN
BEGIN TRY
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
SET @ReturnCode = ERROR_NUMBER();
SET @ReturnMessage = ERROR_MESSAGE();
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE
@ReturnCode int
,@ReturnMessage nvarchar(2048);
EXECUTE dbo.TestReturnCodeParameter
@ReturnError = 0 -- Set to 1 will simulate a return code (8134) and return message (Divide by zero error encountered.) in the output parameters. --
,@ReturnCode = @ReturnCode OUTPUT
,@ReturnMessage = @ReturnMessage OUTPUT;
SELECT ReturnCode = @ReturnCode, ReturnMessage = @ReturnMessage;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestRAISERROR (@ThowSystemError bit = 0, @ThowCustomError bit = 0)
AS
BEGIN
/* New applications should use THROW instead of RAISERROR. https://docs.microsoft.com/en-us/sql/t-sql/language-elements/raiserror-transact-sql?view=sql-server-ver15#:~:text=the%20raiserror%20statement%20does%20not%20honor%20set%20xact_abort.%20new%20applications%20should%20use%20throw%20instead%20of%20raiserror. */
/* SET NOCOUNT, XACT_ABORT ON; */
SET NOCOUNT ON; /* The RAISERROR statement does not honor SET XACT_ABORT. */
IF @ThowSystemError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe1;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
DECLARE @ErrorMessage nvarchar(2048) = ERROR_MESSAGE();
RAISERROR(@ErrorMessage, 16, 1);
RETURN 1;
END CATCH;
END;
IF @ThowCustomError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RAISERROR(N'My Custom Error.', 16, 1);
RETURN 1;
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int;
EXECUTE @ReturnCode = dbo.TestRAISERROR
-- Set both parameters to 0 (zero) will not throw an error --
@ThowSystemError = 0 -- Set to 1 will throw a system generated error (50000: Divide by zero error encountered.) --
,@ThowCustomError = 0; -- Set to 1 will throw a system generated error (50000: My Custom Error.) --
SELECT ReturnCode = @ReturnCode
GO
*/
Scalar Function Is Not Inlineable
Check Id: 25
Your scalar function is not inlineable. This means it will perform poorly.
Review the Inlineable scalar UDFs requirements to determine what changes you can make so it can go inline. If you cannot, you should in-line your scalar function in SQL query. This means duplicate the code you would put in the scalar function in your SQL code. SQL Server 2019 & Azure SQL Database (150 database compatibility level) can inline some scalar functions.
- See 05c Blueprint Functions Scalar Function Rewrites Demo video by Erik Darling to see how to rewrite T-SQL Scalar User Defined Function into a Inline Table Valued function.
Microsoft has been removing (instead of fixing) the inlineablity of scalar functions with every cumulative update. If your query requires scalar functions, you should ensure they are being inlined. Reference: Inlineable scalar UDFs requirements
Run this query to check if your function is inlineable. (SQL Server 2019+ & Azure SQL Server)
SELECT
[Schema] = SCHEMA_NAME(O.schema_id)
,Name = O.name
,FunctionType = O.type_desc
,CreatedDate = O.create_date
FROM
sys.sql_modules AS SM
INNER JOIN sys.objects AS O ON O.object_id = SM.object_id
WHERE
SM.is_inlineable = 1;
Scalar UDFs typically end up performing poorly due to the following reasons:
Iterative invocation: UDFs are invoked in an iterative manner, once per qualifying tuple. This incurs additional costs of repeated context switching due to function invocation. Especially, UDFs that execute Transact-SQL queries in their definition are severely affected.
Lack of costing: During optimization, only relational operators are costed, while scalar operators are not. Prior to the introduction of scalar UDFs, other scalar operators were generally cheap and did not require costing. A small CPU cost added for a scalar operation was enough. There are scenarios where the actual cost is significant, and yet remains underrepresented.
Interpreted execution: UDFs are evaluated as a batch of statements, executed statement-by-statement. Each statement itself is compiled, and the compiled plan is cached. Although this caching strategy saves some time as it avoids recompilations, each statement executes in isolation. No cross-statement optimizations are carried out.
Serial execution: SQL Server does not allow intra-query parallelism in queries that invoke UDFs.
Using User-Defined Scalar Function
Check Id: 24
You should inline your scalar function in SQL query. This means duplicate the code you would put in the scalar function in your SQL code. SQL Server 2019 & Azure SQL Database (150 database compatibility level) can inline some scalar functions.
Microsoft has been removing (instead of fixing) the inlineablity of scalar functions with every cumulative update. If your query requires scalar functions you should ensure they are being inlined. Reference: Inlineable scalar UDFs requirements
Run this query to check if your function is inlineable. (SQL Server 2019+ & Azure SQL Server)
SELECT
[Schema] = SCHEMA_NAME(O.schema_id)
,Name = O.name
,FunctionType = O.type_desc
,CreatedDate = O.create_date
FROM
sys.sql_modules AS SM
INNER JOIN sys.objects AS O ON O.object_id = SM.object_id
WHERE
SM.is_inlineable = 1;
Scalar UDFs typically end up performing poorly due to the following reasons:
Iterative invocation: UDFs are invoked in an iterative manner, once per qualifying tuple. This incurs additional costs of repeated context switching due to function invocation. Especially, UDFs that execute Transact-SQL queries in their definition are severely affected.
Lack of costing: During optimization, only relational operators are costed, while scalar operators are not. Prior to the introduction of scalar UDFs, other scalar operators were generally cheap and did not require costing. A small CPU cost added for a scalar operation was enough. There are scenarios where the actual cost is significant, and yet remains underrepresented.
Interpreted execution: UDFs are evaluated as a batch of statements, executed statement-by-statement. Each statement itself is compiled, and the compiled plan is cached. Although this caching strategy saves some time as it avoids recompilations, each statement executes in isolation. No cross-statement optimizations are carried out.
Serial execution: SQL Server does not allow intra-query parallelism in queries that invoke UDFs.
Not Using SET NOCOUNT ON in Stored Procedure or Trigger
Check Id: 19
Use SET NOCOUNT ON; at the beginning of your SQL batches, stored procedures for report output and triggers in production environments, as this suppresses messages like ‘(10000 row(s) affected)’ after executing INSERT, UPDATE, DELETE and SELECT statements. This improves the performance of stored procedures by reducing network traffic.
SET NOCOUNT ON; is a procedural level instructions and as such there is no need to include a corresponding SET NOCOUNT OFF; command as the last statement in the batch.
SET NOCOUNT OFF; can be helpful when debugging your queries in displaying the number of rows impacted when performing INSERTs, UPDATEs and DELETEs.
CREATE OR ALTER PROCEDURE dbo.PersonInsert
@PersonId int
,@JobTitle nvarchar(100)
,@HiredOn date
,@Gender char(1)
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO
dbo.Person (PersonId, JobTitle, HiredOn, Gender)
SELECT
PersonId = @PersonId,
JobTitle = 'CEO',
HiredOn = '5/2/1971',
Gender = 'M';
END;
Using NOLOCK (READ UNCOMMITTED)
Check Id: 15
Using WITH (NOLOCK), WITH (READUNCOMMITTED) and TRANSACTION ISOLATION LEVEL READ UNCOMMITTED does not mean your SELECT query does not take out a lock, it does not obey locks.
Can NOLOCK be used when the data is not changing? Nope. It has the same problems.
Problems
- You can see rows twice
- You can skip rows altogether
- You can see records that were never committed
- Your query can fail with an error “could not continue scan with
NOLOCKdue to data movement”
These problems will cause non-reproducible errors. You might end up blaming the issue on user error which will not be accurate.
Only use NOLOCK when the application stakeholders understand the problems and approve of them occurring. Get their approval in writing to CYA.
Alternatives
- Index Tuning
- Use READ COMMITTED SNAPSHOT ISOLATION (RCSI).
- On by default in Azure SQL Server databases, local SQL Servers should be checked for TempDB latency before enabling
Not Using Table Alias
Check Id: 124 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use aliases for your table names in most multi-table T-SQL statements; a useful convention is to make the alias out of the first or first two letters of each capitalized table name, e.g., “Phone” becomes “P” and “PhoneType” becomes “PT”.
If you would have duplicate two-character aliases, choose a third letter from each. “PhoneType” becomes “PHT” and “PlaceType” becomes “PLT”.
Ensure you use AS between the table name and the alias like [TABLE-Name] AS [ALIAS]. AS should be used to make it clear that something is being given a new name and easier to spot. This rule also applies for column aliases if the column aliases is not listed first.
Do not use table aliases like S1, S2, S3. Make your aliases meaningful.
SELECT
P.PhoneId
,P.PhoneNumber
,PT.PhoneTypeName
FROM
dbo.Phone AS P
INNER JOIN dbo.PhoneType AS PT
ON P.PhoneTypeId = PT.PhoneTypeId;
Not Using Column List For INSERT
Check Id: 125 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Always use a column list in your INSERT statements. This helps in avoiding problems when the table structure changes (like adding or dropping a column).
INSERT INTO
dbo.Person (PersonId, JobTitle, HiredOn, Gender)
SELECT
PersonId = 1
,JobTitle = 'CEO'
,HiredOn = '5/2/1971'
,Gender = 'M';
Not Using SQL Formatting
Check Id: 126 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
SQL code statements should be arranged in an easy-to-read manner. When statements are written all on one line or not broken into smaller easy-to-read chunks, it is hard to decipher.
Your SQL code should be formatted in a consistent manner so specific elements like keywords, data types, table names, functions can be identified at a quick glance.
Use one of the two RedGate SQL Prompt formatting styles “Team Collapsed” or “Team Expanded”. If you edit T-SQL code that was in a one of the two styles, put the style back to its original style after you completed editing.
Not Using UPPERCASE for Keywords
Check Id: 127 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Keywords like SELECT, FROM, GROUP BY should be in UPPERCASE.
Not Converting to Unicode
Check Id: 128 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You need to put an N in from of your strings to ensure the characters are converted to Unicode before being placed into a nvarchar column.
In the example below FirstName is varchar(100) and LastName is nvarchar(100).
INSERT INTO dbo.Person (FirstName, LastName)
VALUES ('Kevin', N'马丁');
Not converting to Unicode for nvarchar() columns will also cause implicit conversions which will make a query non-SARGable in WHERE clauses.
Not Using lower case for Data Types
Check Id: 129 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Data types should be lower cased to match the exact case that is in the SELECT * FROM sys.types; table. This will ensure collation differences won’t cause unexpected errors.
Use: DECLARE @Id AS int instead of: DECLARE @Id AS INT
Use:
CREATE TABLE dbo.Person (
PersonId int IDENTITY(1, 1) NOT NULL
,FirstName nvarchar(50) NULL
,LastName varchar(50) NULL
);
instead of:
CREATE TABLE dbo.Person (
PersonId INT IDENTITY(1, 1) NOT NULL
,FirstName NVARCHAR(50) NULL
,LastName VARCHAR(50) NULL
);
Set Option Cause Recompile
Check Id: 130 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Setting options in batches, stored procedures, and triggers cause recompilation. They should be compiled just once and have their plans reused for subsequent calls. The query will be more performant and use less memory.
Using Column Number in ORDER BY
Check Id: 131 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use the column name in your ORDER BY instead of the column number. The use of constants in the ORDER BY is deprecated for future removal. It makes it difficult to understand the code at a glance and leads to issue when alter the order of the columns in the SELECT.
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
ORDER BY
2;
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
ORDER BY
P.LastName ASC;
Commented Out Code
Check Id: 132 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Remove commented out code.
Commented code hides what’s important and it is out of date. Rely on the version control system to keep track of previous code.
Not Using Location Comment
Check Id: 133 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
When creating dynamic SQL or software originated SQL code, insert a comment explaining where it came from, be it a stored procedure name, method name, function name, some name that will help track down what is generating this SQL Code.
When looking at the SQL Server execution plan cache for dynamic SQL and SQL originating in software code, we cannot see the parent object like we can with non-dynamic database stored procedures or functions. It only reports as ‘Statement’ for Query Type. The SQL command location comment helps a team member or query tuner easier identify the lineage of which piece of code built the SQL command. The location comment can be found in the stored query plan by viewing the query text.
Use static text for the location comment and do not create dynamic comments. Static comment text allows for a single plan cache to be created and reused.
Below is good:
/* dbo.MyStoredProcedure */
SELECT * FROM dbo.Person WHERE FirstName = 'Kevin'
It is tempting to add things like the date and time or the username who ran the SQL command. Dynamic comment text will create plan cache pollution having multiple plan caches.
Below is bad:
/* Namespace.MyMethod – ran at 2022-01-28 22:48:12.423 */
SELECT * FROM dbo.Person WHERE FirstName = 'Kevin'
Using Double Dash Instead of Block Comment
Check Id: 134 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use block comments /* comment */ instead of double-dash -- comment comments in your T-SQL code. Double-dash comments that are copy and pasted when performance tuning makes it difficult to know where the single line comment ends.
If this is the query and double-dash -- comment comment is used:
SELECT
*
FROM
dbo.Person
WHERE
FirstName = 'Kevin' -- This line is a comment
AND LastName = 'Martin'
ORDER BY
LastName ASC;
It turns into this in monitoring tools and Dynamic Management Views:
SELECT * FROM dbo.Person WHERE FirstName = 'Kevin' -- This line is a comment AND LastName = 'Martin' ORDER BY LastName ASC;
You cannot tell where the query ends and it will break tools like Redgate SQL Prompt.
The better method is to use the block style comments /* comment */ like:
SELECT
*
FROM
dbo.Person
WHERE
FirstName = 'Kevin' /* This line is a comment */
AND LastName = 'Martin'
ORDER BY
LastName;
The collapse query below will format correctly in SSMS with Redgate SQL Prompt.
SELECT * FROM dbo.Person WHERE FirstName = 'Kevin' /* This line is a comment */ AND LastName = 'Martin' ORDER BY LastName;
Not Using Code Comments
Check Id: 135 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Important code blocks within stored procedures and functions should be commented. Brief functionality descriptions should be included where important or complicated processing is taking place.
Stored procedures and functions should include at a minimum a header comment with a brief overview of the batch’s functionality and author information.
You can skip including the Author, Created On & Modified On details when you use source control. (You should be using source control!)
/**********************************************************************************************************************
** Author: Your Name
** Created On: 1/22/20??
** Modified On: 8/5/20??
** Description: Description of what the query does goes here. Be specific and don't be afraid to say too much. More is
better every single time. Think about "what, when, where, how and why" when authoring a description.
**********************************************************************************************************************/
Not Using Table Schema
Check Id: 136 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Prefix all database objects like table names and stored procedures with the schema (in most cases “dbo.”). This results in a performance gain as the optimizer does not have to perform a lookup on execution as well as minimizing ambiguities in your T-SQL.
By including the schema, we avoid certain bugs, minimize the time the engine spends searching for the procedure, and help ensure that cached query plans for the procedures get reused.
Not including the schema on a stored procedure will lead to compile locks. See Additional Scenarios that lead to compile locks (1. Stored Procedure is executed without Fully Qualified Name)
Using SELECT *
Check Id: 23
Do not use the SELECT * in production code unless you have a good reason, instead specify the field names and bring back only those fields you need; this optimizes query performance and eliminates the possibility of unexpected results when fields are added to a table.
SELECT * in IF EXISTS statements are OK. “*” in math equations is OK.
Reasons not to use SELECT *:
- Unnecessary Input / Output will need to read more SQL Server 8k pages than required
- Increased Network Traffic will take more bandwidth for more data
- More Application Memory will need more memory to hold more data
- Dependency on Order of Columns on Result Set will mess up the order the columns are returned
- Breaks Views While Adding New Columns to a Table the view columns are created at the time of the view creation, you will need to refresh “sp_refreshview()”
- Copying Data From One Table to Another your SELECT * INTO table will break with new columns
Using Hardcoded Database Name Reference
Check Id: 9
Use two-part instead three-part names for tables. You should use “dbo.Customer” instead of “DatabaseName.dbo.Customer” in the FROM clause.
It is common to need a database to operate under different names.
- In development, test, production environments
- This allows the same code to execute if the database names are “CompanyName-Prod” or “CompanyName-Dev”
- When branching database code in source control
- You might want to name a database after a feature branch on the same SQL Server instance.
- When building database code
- To validate database objects compiled from a source, it is best to not have the database name hardcoded. If you use a hardcoded name you need to ensure that only one build server can run a build for that database instance.
Using @@IDENTITY Instead of SCOPE_IDENTITY
Check Id: 137 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The generation of an identity value is not transactional, so in some circumstances, @@IDENTITY returns the wrong value and not the value from the row you just inserted. This is especially true when using triggers that insert data, depending on when the triggers fire. The SCOPE_IDENTITY function is safer because it always relates to the current batch (within the same scope). Also consider using the IDENT_CURRENT function, which returns the last identity value regardless of session or scope. The OUTPUT clause is a better and safer way of capturing identity values.
Not Accounting for Time in a Range
Check Id: 138 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
You need to account for the end range being one of the datetime data types, or you might be excluding rows.
This can be an exclusion problem for dates with times and utilizing BETWEEN. This can also occur using >= ... AND <= ... methodology. A day ends at “23:59:59.9999999” or shorter based on the datetime length, right before the chime of midnight.
BETWEEN is ambiguous. If a restaurant states they are open 9-5, that include all times between 9:00 AM and 5:00 PM. When you score a goal in hockey, the goal only counts when the puck is between the goal posts. In SQL Server, BETWEEN is a closed interval that includes both ends of the range. Some consider avoiding BETWEEN for date range queries. Source Bad Habits to Kick: Mis-handling date / range queries by Aaron Bertrand
There are two examples below to accomplish this using a subtraction trick.
With >= … AND <= …
USE WideWorldImporters;
GO
UPDATE Sales.Orders SET PickingCompletedWhen = '2013-01-09 23:59:59.9999999' WHERE OrderId = 469
DECLARE
@PickingCompletedWhenFrom datetime2(7) = '2013-01-09'
,@PickingCompletedWhenTo datetime2(7) = '2013-01-09';
SELECT
O.OrderID
,O.PickingCompletedWhen
FROM
Sales.Orders AS O
WHERE
O.PickingCompletedWhen >= @PickingCompletedWhenFrom
AND O.PickingCompletedWhen <= DATEADD(NANOSECOND, -1, DATEADD(DAY, 1, @PickingCompletedWhenTo))
ORDER BY
O.PickingCompletedWhen DESC;
With BETWEEN
USE WideWorldImporters;
GO
UPDATE Sales.Orders SET PickingCompletedWhen = '2013-01-09 23:59:59.9999999' WHERE OrderId = 469
DECLARE
@PickingCompletedWhenFrom datetime2(7) = '2013-01-09'
,@PickingCompletedWhenTo datetime2(7) = '2013-01-09';
SELECT
O.OrderID
,O.PickingCompletedWhen
FROM
Sales.Orders AS O
WHERE
O.PickingCompletedWhen BETWEEN @PickingCompletedWhenFrom AND DATEADD(NANOSECOND, -1, DATEADD(DAY, 1, @PickingCompletedWhenTo))
ORDER BY
O.PickingCompletedWhen DESC;
Using Non-ANSI NOT EQUAL Operator
Check Id: 139 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use ANSI-style NOT_EQUAL operator <>.
The != symbol for not equal is not part of the SQL language. It is understood but only for the sake of backward-compatibility.
Using Old Sybase JOIN Syntax
Check Id: 140 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
The deprecated syntax (which includes defining the join condition in the WHERE clause) is not standard SQL and is more difficult to inspect and maintain. Parts of this syntax are completely unsupported in SQL Server 2012 or higher.
The “old style” Microsoft/Sybase JOIN style for T-SQL, which uses the =* and *= syntax, has been deprecated and is no longer used. Queries that use this syntax will fail when the database engine level is 10 (SQL Server 2008) or later (compatibility level 100).
Not Specifying JOIN Type
Check Id: 141 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
It is always better to specify the type of join you require, INNER JOIN, LEFT OUTER JOIN (LEFT JOIN), RIGHT OUTER JOIN (RIGHT JOIN), FULL OUTER JOIN (FULL JOIN) and CROSS JOIN, which has been standard since ANSI SQL-92 was published.
While you can choose any supported JOIN style, without affecting the query plan used by SQL Server, using the ANSI-standard syntax will make your code easier to understand, more consistent, and portable to other relational database systems.
Using LEFT OUTER JOIN Instead of INNER JOIN
Check Id: 142 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use INNER JOIN when rows will match in both tables. Rows will match in both tables if the foreign key column does not allow NULL.
Using INNER JOIN Instead of LEFT OUTER JOIN
Check Id: 143 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Use LEFT OUTER JOIN when rows might not always match in both tables. Rows might not match in both tables if the foreign key column allows NULL.
Order of Columns in JOIN Clause
Potential Finding: Backward Order of Columns in JOIN Clause
Check Id: 144 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Emergent recommends the Microsoft Docs column order in JOIN clauses for consistency noted in the “Do This” code below.
It is always recommended to adapt the naming and coding conventions of inherited projects.
There is a setting for this in Redgate SQL Prompt: Click the ‘SQL Prompt’ navigation menu > Click ‘Join conditions’ in the ‘Suggestions’ section > Check/tick the ‘Swap order of columns in join clauses’ checkbox in the ‘Column order’ section > Click the ‘OK’ button.
In the example below, the StateProvince table is joined to the CountryRegion table. StateProvince -> CountryRegion.
Do This:
SELECT
SP.StateProvinceCode
FROM
dbo.StateProvince AS SP
INNER JOIN dbo.CountryRegion AS CR
ON SP.CountryRegionId = CR.CountryRegionId; /* <-- Look Here */
Not This:
SELECT
SP.StateProvinceCode
FROM
dbo.StateProvince AS SP
INNER JOIN dbo.CountryRegion AS CR
ON CR.CountryRegionId = SP.CountryRegionId; /* <-- Look Here */
View Usage
Check Id: 145 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Ask yourself what you are gaining by creating a view.
Views do not lend themselves to being deeply nested. Views that reference views are difficult to maintain.
A view can be helpful with the use cases below and should be no less performant, it matters what you put in the view that will give you problems.
- View Use Cases
- Create a temporary indexed view for performance issues you cannot solve without changing T-SQL code
- You need to retire a table and use a new table with similar data (still should be a temporary use)
- For security reasons to expose only specific data to a database role
- As an interface layer for a client that does not support a table or stored procedure data source
- Abstracting complicated base tables
- Data aggregation like
SUM(),AVG(),COUNT(),MIN(),MAX(), …- It is best to include this aggregation code in a stored procedure, but if there is a need to not have duplicated business logic code in multiple stored procedures, these data aggregation views can be helpful.
- If a view does not work and you need parameters, try an Inline Table Valued Function (iTVF). Views and iTVF at runtime are both inlined and treaded similarly to derived tables or CTEs.
- These aggregation views can be used to
JOINon with single row data like an Event. The aggregations would be used to sum up the Attendees joined on the EventId. - Immutable (unchanging) records can have the parent table’s column value set inside a transaction with the child rows.
- It is best to include this aggregation code in a stored procedure, but if there is a need to not have duplicated business logic code in multiple stored procedures, these data aggregation views can be helpful.
Invalid Objects
Check Id: 146 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
This check found objects that were deleted, renamed. Use can also run “Find Invalid Objects” with RedGate SQL Prompt in SQL Server Management Studio.
Try running EXEC sp_refreshsqlmodule or sp_refreshview.
JSON Explicit Schema
Check Id: 159 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
Explicitly defining the schema JSON columns using with_clause is more performant.
If you are required to use JSON string in the relational database and need to frequent parse the JSON string, you could create a computed column using JSON_VALUE(expression, path) and create an index
JSON Performance
Check Id: 160 Not implemented yet. Click here to add the issue if you want to develop and create a pull request.
If you are required to use JSON strings in the relational database and need to frequent parse the JSON string, create a computed column on the table using JSON_VALUE(expression, path) and create an index.
ALTER TABLE dbo.DeliveryInventory ADD MakeName AS JSON_VALUE(JSONAttributes, '$.Make');
CREATE NONCLUSTERED INDEX DealerInventory_MakeName ON dbo.DeliveryInventory (MakeName ASC);